Zipline
Using Data
Pipeline in Algorithms
As covered in the Initialization section, Pipelines can be replicated using Universe Selection in QuantConnect, albeit with some additional steps in between and a performance impact.
In this section, we will construct and define an equivalent pipeline model using universe selection in QuantConnect. We will filter our data set in Coarse and Fine, and apply an additional filter to historical data with a rolling window.
We first create a skeleton algorithm definition to begin setting up our Pipeline. Note that this algorithm will allow all equities through, which will have a substantial performance impact on our algorithm.
class MyPipelineAlgorithm(QCAlgorithm):
def initialize(self) -> None:
self.set_start_date(2020, 1, 1)
self.set_end_date(2020, 10, 20)
self.add_universe(self.coarse_selection_function, self.fine_selection_function)
def coarse_selection_function(self, coarse: List[CoarseFundamental]) -> List[Symbol]:
# Allows all Symbols through, no filtering applied
return [coarse_data.symbol for coarse_data in coarse]
def fine_selection_function(self, fine: List[FineFundamental]) -> List[Symbol]:
# Allows all Symbols through, no filtering applied
return [fine_data.symbol for fine_data in fine]
The skeleton algorithm is the equivalent of the Pipeline call below.
from quantopian.pipeline import Pipeline
from quantopian.pipeline.domain import US_EQUITIES
from quantopian.research import run_pipeline
pipe = Pipeline(columns={}, domain=US_EQUITIES)
run_pipeline(pipe, '2020-01-01', '2020-10-20')
The equivalent of Pipeline(screen=...) resolves to the filter applied at the Coarse and Fine stages
of universe selection.
Let's define a filter of stocks with a dollar volume greater than $50000000 USD, as well as
a rolling thirty day return greater than 2%. Once we've initially filtered the Symbols in Coarse Universe Selection,
let's define a final filter only allowing stocks with EPS greater than 0.
Beware of making History() calls with many Symbols. It could potentially cause your algorithm to
run out of system resources (i.e. RAM) and reduce performance of your algorithm on universe selection.
from datetime import datetime, timedelta
class MyPipelineAlgorithm(QCAlgorithm):
def initialize(self) -> None:
self.set_start_date(2020, 1, 1)
self.set_end_date(2020, 10, 20)
self.add_universe(self._coarse_selection_function, self._fine_selection_function)
def _coarse_selection_function(self, coarse: List[CoarseFundamental]) -> List[Symbol]:
# Allows all Symbols through, no filtering applied
dollar_volume_filter_symbols = [coarse_data.symbol for coarse_data in coarse if coarse_data.dollar_volume > 50000000]
# Make a history call to calculate the 30 day rolling returns
df = self.history(dollar_volume_filter_symbols, self.time - timedelta(days=60), self.time, Resolution.DAILY)
# Compute the rolling 30 day returns
df = df['close'].groupby(level=0).filter(lambda x: len(x) >= 30).groupby(level=0).apply(lambda x: (x.iloc[-1] - x.iloc[-30]) / x.iloc[-30])
# Finally, apply our filter
dataframe_screen = df[df > 0.02]
# Filters out any Symbol that is not in the DataFrame
return [s for s in dollar_volume_filter_symbols if str(s) in dataframe_screen]
def _fine_selection_function(self, fine: List[FineFundamental]) -> List[Symbol]:
# We receive the filtered symbols from before, and we filter by EPS > 0 in this step
return [s.symbol for s in fine if s.earning_reports.basic_eps.three_months > 0]
This class definition is now roughly equivalent to the following CustomFactor and Pipeline call in Quantopian, excluding the EPS filtering.
from quantopian.pipeline.filters import QTradableStocksUS
from quantopian.pipeline.factors import AverageDollarVolume
class PercentageChange(CustomFactor):
def compute(self, today, assets, out, values):
out[:] = (values[-1] - values[0]) / values[0]
dollar_volume = AverageDollarVolume(window_length=5)
dollar_volume_filter = (dollar_volume > 50000000)
pipe = Pipeline(
columns={
"percent_change": PercentageChange(inputs=[USEquityPricing.close], window_length=30)
},
screen=(QTradableStocksUS() & dollar_volume_filter)
)
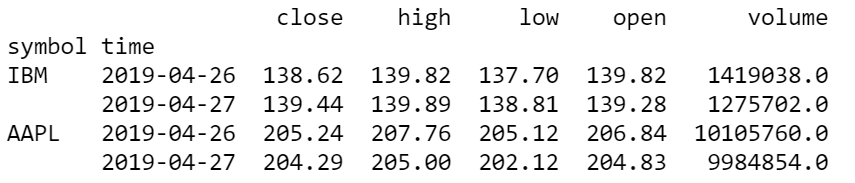
An example of the shape of the DataFrame returned from History is shown below.
The DataFrame has a MultiIndex, with level=0 being the Symbol, and level=1 being the Time
for that point of data. You can index the Symbol/level=0 index by using either the SecurityIdentifier string (e.g. df.loc["AAPL R735QTJ8XC9X"]) or
with the ticker of the Symbol (e.g. df.loc["AAPL"])
BarData Lookup
Similar but different, the Quantopian BarData object, and the QuantConnect Slice object
both provide data to the user's algorithm as point-in-time data.
In Quantopian, data is handled via the handle_data(context, data) function.
In QuantConnect, data is handled via the OnData(self, slice) method.
Both of these functions accept data whenever new data exists for a given point in time.
Although these two functions share the same method signature, the handling of the data is different.
BarData vs. Slice
BarData is the primary mechanism to retrieve the point-in-time data, as well as requesting
history for any given securities in Quantopian.
The following code retrieves daily historical data from 30 days into the past, as well as getting
the most recent data for AAPL at the current point-in-time.
Quantopian
def initialize(context):
context.aapl = sid(24)
def handle_data(context, data):
# Gets a DataFrame of AAPL history going back 30 days
aapl_history = data.history(context.aapl, fields=["open", "high", "low", "close", "volume"], 30, "1d")
# Gets a pandas Series of the most recent AAPL data
aapl_current = data.current(context.aapl, fields=["open", "high", "low", "close", "volume"])
QuantConnect
from datetime import timedelta
class MyHistoryAlgorithm(QCAlgorithm):
def initialize(self) -> None:
self.aapl = self.add_equity("AAPL", Resolution.DAILY)
def on_data(self, slice: Slice) -> None:
# Gets a DataFrame of AAPL history going back 30 days
aapl_history = self.history([self.aapl.symbol], timedelta(days=30), Resolution.DAILY)
# Gets the most recent AAPL Trade data (OHLCV)
aapl_current = slice.bars[self.aapl.symbol]
Slice represents a single point in time, and does not provide the functionality to access historical data itself.
To access historical data in an algorithm, use the algorithm's self.History() call to request
a pandas DataFrame of historical data.
In Slice, the data that is accessed is not a pandas DataFrame, but rather a single object containing data for a single point in time.
The TradeBar class, for example, only contains scalar values of OHLCV, rather than return a DataFrame of OHLCV values.
Since the data Slice contains is point-in-time, there will be only a single trade/quote bar per Symbol whenever OnData(self, data) is called.
QuantConnect provides Quote (NBBO) data for use in your algorithm, otherwise known as a QuoteBar.
Quote data is only accessible when an algorithm is set to consume Tick, Second, or Minutely data.
You can access Trade (OHLCV) data by accessing the Bars attribute of Slice.
You can access Quote (Bid(OHLCV), Ask(OHLCV)) data by accessing the QuoteBars attribute of Slice.
Both of the Bars and QuoteBars attributes are similar to Python dictionaries, and can
be used as such. To check to see if there exists a new piece of data for a given security, you can use Python's in operator
on Bars and or QuoteBars.
You can also choose to iterate on all data received by calling the Values attribute of the Bars or QuoteBars attributes, which will
return either a list of TradeBar or QuoteBar objects.
The TradeBar object contains the Open, High, Low, Close, Volume, Timetime, EndTimeend_time, and Symbol attributes.
The QuoteBar object contains the following attributes:
Bid.Open,Bid.High,Bid.Low,Bid.Close,LastBidSizeAsk.Open,Ask.High,Ask.Low,Ask.Close,LastAskSizeTimetime,EndTimeend_time, andSymbol.
Note that the Bid and Ask attributes can potentially be None if no bid/ask data exists
at a given point-in-time.
The example below shows the different ways to access TradeBar and QuoteBar
data, as well as requesting 30 days of AAPL historical data.
from datetime import datetime, timedelta
class MyDataAlgorithm(QCAlgorithm):
def initialize(self) -> None:
self.aapl_security = self.add_equity("AAPL", Resolution.DAILY)
self.aapl_symbol = self.aapl_security.symbol
def on_data(self, slice: Slice) -> None:
# Gets 30 days of AAPL history
aapl_history = self.history([self.aapl_symbol], timedelta(days=30), Resolution.DAILY)
# We must first check to make sure we have AAPL data, since this point-in-time
# might not have had any trades for AAPL (this is in case you trade a low
# liquidity asset. The data can potentially be missing for a point-in-time).
if self.aapl_symbol in slice.bars:
aapl_current_trade = slice.bars[self.aapl_symbol]
self.log(f"{self.time} :: TRADE :: {self.aapl_symbol} - O: {aapl_current_trade.open} H: {aapl_current_trade.high} L: {aapl_current_trade.low} C: {aapl_current_trade.close} V: {aapl_current_trade.volume}")
# Check to make sure we have AAPL data first, since there might not have
# been any quote updates since the previous for AAPL (this is in case you trade
# a low liquidity asset. The data can potentially be missing for a point-in-time).
if self.aapl_symbol in slice.quote_bars:
aapl_current_quote = slice.quote_bars[self.aapl_symbol]
if aapl_current_quote.bid is not None:
bid = aapl_current_quote.bid
self.log(f"{self.time} :: QUOTE :: {self.aapl_symbol} - Bid O: {bid.open} Bid H: {bid.high} Bid L: {bid.low} Bid C: {bid.close} Bid size: {aapl_current_quote.last_bid_size}")
if aapl_current_quote.ask is not None:
ask = aapl_current_quote.ask
self.log(f"{self.time} :: QUOTE :: {self.aapl_symbol} - Ask O: {ask.open} Ask H: {ask.high} Ask L: {ask.low} Ask C: {ask.close} Ask size: {aapl_current_quote.last_ask_size}")
You can also see our Videos. You can also get in touch with us via Discord.
Did you find this page helpful?