Popular Libraries
Tslearn
Create Subscriptions
In the Initializeinitialize method, subscribe to some data so you can train the tslearn model.
# Add securities and save a reference to their Symbol objects.
tickers = ["SPY", "QQQ", "DIA",
"AAPL", "MSFT", "TSLA",
"IEF", "TLT", "SHV", "SHY",
"GLD", "IAU", "SLV",
"USO", "XLE", "XOM"]
symbols = [self.add_equity(ticker, Resolution.DAILY).symbol for ticker in tickers]
Build Models
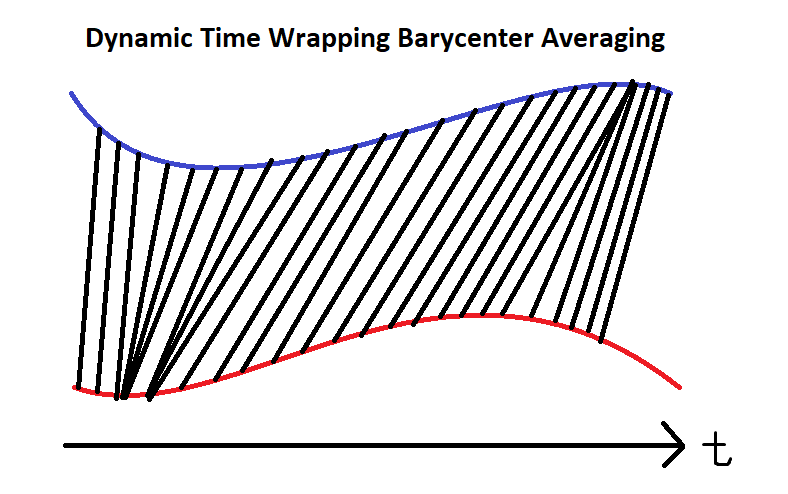
In this example, train a model that clusters the universe of Equities into distinct groups and then allocate an equal portion of the portfolio to each cluster. To cluster the securities, instead of using a real-time comparison, apply Dynamic Time Wrapping Barycenter Averaging (DBA) to their historical prices and then run a k-means clustering algorithm. DBA is a technique of averaging a few time-series into a single one without losing much of their information. Since not all time-series move efficiently like in ideal EMH assumption, this technique allows similarity analysis of different time-series with sticky lags. The following image shows a visualization of the process. For more information about the technical details, see Dynamic Time Warping in the tslearn documentation.
To perform DBA and then cluster the securities by k-means, create a TimeSeriesKMeans model:
# Create a model to cluster the time series into 6 groups using DTW for similarity measurement. self.model = TimeSeriesKMeans(n_clusters=6, metric="dtw")
Train Models
You can train the model at the beginning of your algorithm and you can periodically re-train it as the algorithm executes.
Warm Up Training Data
You need historical data to initially train the model at the start of your algorithm. To get the initial training data, in the Initializeinitialize method, make a history request.
# Fill a RollingWindow with 2 years of historical closing prices.
training_length = 252
self.training_data = {}
history = self.history(self.symbols, training_length, Resolution.DAILY).unstack(0).close
for symbol in self.symbols:
self.training_data[symbol] = RollingWindow(training_length)
for close_price in history[symbol]:
self.training_data[symbol].add(close_price)
Define a Training Method
To train the model, define a method that fits the model with the training data.
# Prepare feature and label data for training by processing the RollingWindow data into a time series.
def get_features(self):
close_price = pd.DataFrame({symbol: list(data)[::-1] for symbol, data in self.training_data.items()})
log_price = np.log(close_price)
log_normal_price = (log_price - log_price.mean()) / log_price.std()
return log_normal_price
def my_training_method(self):
features = self.get_features()
self.model.fit(features.T.values)
Set Training Schedule
To train the model at the beginning of your algorithm, in the Initializeinitialize method, call the Traintrain method.
# Train the model initially to provide a baseline for prediction and decision-making. self.train(self.my_training_method)
To periodically re-train the model as your algorithm executes, in the Initializeinitialize method, call the Traintrain method as a Scheduled Event.
# Train the model every Sunday at 8:00 AM self.train(self.date_rules.every(DayOfWeek.SUNDAY), self.time_rules.at(8, 0), self.my_training_method)
Update Training Data
To update the training data as the algorithm executes, in the OnDataon_data method, add the current TradeBar to the RollingWindow that holds the training data.
# Add the latest price to the training data to ensure the model is trained with the most recent market data.
def on_data(self, slice: Slice) -> None:
for kvp in slice.bars:
self.training_data[kvp.key].add(kvp.value.close)
Predict Labels
To predict the labels of new data, in the OnDataon_data method, get the most recent set of features and then call the predict method.
# Get the current feature set and make a prediction. features = self.get_features() self.labels = self.model.predict(features.T.values)
You can use the label prediction to place orders.
# Place orders based on the predicted clusters.
for i in set(self.labels):
assets_in_cluster = features.columns[[n for n, k in enumerate(self.labels) if k == i]]
size = 1/6/len(assets_in_cluster)
self.set_holdings([PortfolioTarget(symbol, size) for symbol in assets_in_cluster])
Save Models
Follow these steps to save tslearn models into the Object Store:
- Set the key name of the model to be stored in the Object Store.
- Call the
GetFilePathget_file_pathmethod with the key. - Delete the current file to avoid a
FileExistsErrorerror when you save the model. - Call the
to_hdf5method with the file path.
# Set the key to store the model in the Object Store for reuse across sessions.
model_key = f"{self.project_id}/model.hdf5"
# Get the file path to correctly save and access the model in Object Store. file_name = self.object_store.get_file_path(model_key)
This method returns the file path where the model will be stored.
import os os.remove(file_name)
# Serialize the model and save it to the file. self.model.to_hdf5(file_name)
Upload Models
If you train models locally or in another environment, you can upload the model files to the Object Store so your algorithms can use them. Use the model key that matches the key your algorithm expects when it calls object_store.get_file_path.
Follow one of these approaches to upload your model files:
LEAN CLI
Run the lean cloud object-store set command to upload a local file to the Object Store.
$ lean cloud object-store set <projectId>/model.hdf5 <pathTo>/model.hdf5
Replace <projectId> with your project Id and <pathTo> with the path to the local model file.
Cloud API
Use the Upload Object Store Files endpoint to upload a model file through the API.
Load Models
You can load and trade with pre-trained tslearn models that saved in Object Store. To load a tslearn model from the Object Store, in the Initializeinitialize method, get the file path to the saved model and then call the from_hdf5 method.
# Load the tslearn model from the Object Store to use its saved state and update it with new data if needed.
def initialize(self) -> None:
model_key = f"{self.project_id}/model.hdf5"
if self.object_store.contains_key(model_key):
file_name = self.object_store.get_file_path(model_key)
self.model = TimeSeriesKMeans.from_hdf5(file_name + ".hdf5")
The ContainsKeycontains_key method returns a boolean that represents if the model_key is in the Object Store. If the Object Store does not contain the model_key, save the model using the model_key before you proceed.
Examples
The following examples demonstrate some common practices for using
Tslearn
library.
Example 1: Dynamic Time Wrapping (DTW) Clustering
The below algorithm makes use of
Tslearn
library to cluster stocks based on their recent year's price movement through DTW Barycenter Averaging. Then, we invest each cluster equally, while investing stocks within cluster equally as well. To ensure the model applicable to the current market environment, we recalibrate the model on every Sunday.
from tslearn.barycenters import softdtw_barycenter
from tslearn.clustering import TimeSeriesKMeans
import joblib
class TslearnExampleAlgorithm(QCAlgorithm):
def initialize(self) -> None:
self.set_start_date(2024, 9, 1)
self.set_end_date(2024, 12, 31)
self.set_cash(100000)
# Request stocks data for model training, clustering and trading.
tickers = ["SPY", "QQQ", "DIA",
"AAPL", "MSFT", "TSLA",
"IEF", "TLT", "SHV", "SHY",
"GLD", "IAU", "SLV",
"USO", "XLE", "XOM"]
self.symbols = [self.add_equity(ticker, Resolution.DAILY).symbol for ticker in tickers]
# 1-year data to train the model.
self._training_length = 252
# Create the DTW model to cluster the stocks.
self.model = TimeSeriesKMeans(n_clusters=6, # We have 6 main groups
metric="dtw")
# Train the model to use the prediction right away.
self.train(self.my_training_method)
# Recalibrate the model weekly to ensure its accuracy on the updated domain.
self.train(self.date_rules.every(DayOfWeek.SUNDAY), self.time_rules.at(8,0), self.my_training_method)
def get_features(self) -> None:
# Get historical close prices and cluster the log-return data, which is more normalized and stationary.
close_price = self.history(self.symbols, self._training_length, Resolution.DAILY).unstack(0).close.dropna(axis=1)
log_price = np.log(close_price)
log_normal_price = (log_price - log_price.mean()) / log_price.std()
return log_normal_price
def my_training_method(self) -> None:
# Prepare the processed training data.
features = self.get_features()
# Recalibrate the model based on updated data.
self.model.fit(features.T.values)
def on_data(self, slice: Slice) -> None:
if not hasattr(self.model, 'cluster_centers_'):
return
# Get prediction by the updated features.
features = self.get_features()
self.labels = self.model.predict(features.T.values)
# Equally invest in each cluster, while investing each stocks within cluster equally to evenly dissipate capital risks at various levels.
for i in set(self.labels):
assets_in_cluster = features.columns[[n for n, k in enumerate(self.labels) if k == i]]
size = 1/6/len(assets_in_cluster)
self.set_holdings([PortfolioTarget(symbol, size) for symbol in assets_in_cluster])
def on_end_of_algorithm(self) -> None:
# Store the model to object store to retrieve it in other instances in case the algorithm stops.
model_key = f"{self.project_id}/model_test.hdf5"
# If the model already exists, delete it so the `to_hdf5` method doesn't raise an error.
if self.object_store.contains_key(model_key):
self.object_store.delete(model_key)
file_name = self.object_store.get_file_path(model_key)
self.model.to_hdf5(file_name)
You can also see our Videos. You can also get in touch with us via Discord.
Did you find this page helpful?