Introduction
In the last chapter we introduced simple linear regression, which has only one independent variable. In this chapter we will learn about linear regression with multiple independent variables.
A simple linear regression model is written in the following form:
A multiple linear regression model with p variables is given by:
Python Implementation
In the last chapter we used the S&P 500 index to predict Amazon stock returns. Now we will add more variables to improve our model's predictions. In particular, we shall consider Amazon's competitors.
from datetime import datetime
qb = QuantBook()
symbols = [qb.AddEquity(ticker).Symbol
for ticker in ["SPY", "AAPL", "AMZN", "EBAY", "WMT"]]
Then we fetch closing prices starting from 2016:
history = qb.History(symbols, datetime(2016, 1, 1), datetime(2017, 1, 1), Resolution.Daily)
After taking log returns of each stock, we concatenate them into a DataFrame, and print out the last 5 rows:
df = np.log(history.close.unstack(0)).diff().dropna()
df.tail()
| Time | AAPL | AMZN | EBAY | SPY | WMT |
|---|---|---|---|---|---|
| 2016-12-24 | 0.001976 | -0.007531 | 0.008427 | 0.001463 | -0.000719 |
| 2016-12-28 | 0.006331 | 0.014113 | 0.014993 | 0.002478 | 0.002298 |
| 2016-12-29 | -0.004273 | 0.000946 | -0.007635 | -0.008299 | -0.005611 |
| 2016-12-30 | -0.000257 | -0.009081 | -0.001000 | -0.000223 | -0.000722 |
| 2016-12-31 | -0.007826 | -0.020172 | -0.009720 | -0.003662 | -0.002023 |
As before, we use the 'statsmodels' package to perform simple linear regression:
import statsmodels.formula.api as sm
simple = sm.ols(formula = 'AMZN ~ SPY', data = df).fit()
print(simple.summary())
| coef | std err | t | P>|t| |
[0.025 |
0.975] |
|
|---|---|---|---|---|---|---|
| Intercept | 0.0001 | 0.001 | 0.105 | 0.917 | -0.002 | 0.002 |
| SPY | 1.0695 | 0.124 | 8.657 | 0.000 | 0.826 | 1.313 |
Similarly, we can build a multiple linear regression model:
model = sm.ols(formula = 'AMZN ~ SPY + AAPL + EBAY + WMT', data = df).fit()
print(model.summary())
| coef | std err | t | P>|t| |
[0.025 |
0.975] |
|
|---|---|---|---|---|---|---|
| Intercept | 0.0001 | 0.001 | 0.136 | 0.892 | -0.002 | 0.002 |
| SPY | 1.0288 | 0.170 | 6.057 | 0.000 | 0.694 | 1.363 |
| AAPL | 0.1574 | 0.084 | 1.879 | 0.061 | -0.008 | 0.322 |
| EBAY | -0.0784 | 0.058 | -1.342 | 0.181 | -0.193 | 0.037 |
| WMT | -0.0810 | 0.089 | -0.907 | 0.365 | -0.257 | 0.095 |
As seen from the summary table, the p-values for Apple, Ebay and Walmart are 0.061, 0.181 and 0.365 respectively, so none of them are significant at a 95% confidence level. The multiple regression model has a higher than the simple one: 0.254 vs 0.234. Indeed, cannot decrease as the number of variables increases. Why? If an extra variable is added to our regression model, but it cannot account for variations in the response (AMZN), then its estimated coefficient will simply be zero. It's as though that variable was never included in the model, so will not change. However, it is not always better to add hundreds of variables or we will overfit our model. We'll talk about this in a later chapter.
Can we improve our model further? Here we try the Fama-French 5-factor model, which is an important model in asset pricing theory. We will cover it in the later tutorials.
The data needed are publicly available on French's website. We have saved a copy for convenience. The following code fetches the data.
from datetime import datetime
url = 'https://raw.githubusercontent.com/QuantConnect/Tutorials/master/Data/F-F_Research_Data_5_Factors_2x3.CSV'
response = qb.Download(url).replace(' ','')
lines = [x.split(',') for x in response.split('\n')[4:]
if len(x.split(',')[0]) == 6 ]
records = {datetime.strptime(line[0], "%Y%m"):line[1:] for line in lines }
fama_table = pd.DataFrame.from_dict(records, orient='index', columns=['Mkt-RF','SMB','HML','RMW','CMA','RF'])
With the data, we can construct a Fama-French factor model:
fama = fama_table['2016']
fama_df = pd.concat([fama, amzn_log], axis = 1)
fama_model = sm.ols(formula = 'Close~MKT+SMB+HML+RMW+CMA', data = fama_df).fit()
print(fama_model.summary())
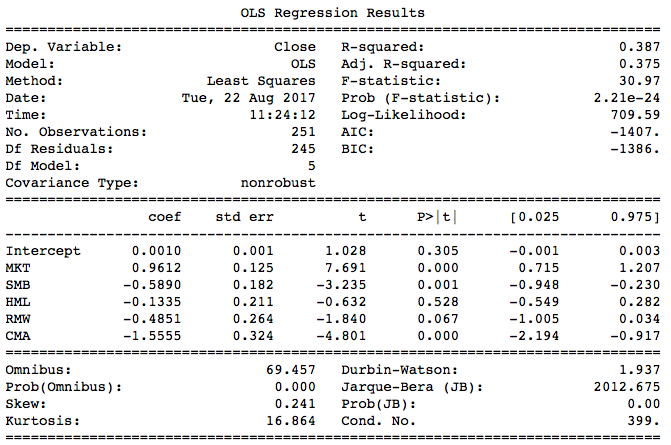
The Fama-French 5-factor model has a higher of 0.387. We can compare the predictions from simple linear regression and Fama-French multiple regression by plotting them together on one chart:
result = pd.DataFrame({'simple regression': simple.predict(),
'fama_french': fama_model.predict(),
'sample': df.amzn}, index = df.index)
# Feel free to adjust the chart size
plt.figure(figsize = (15,7.5))
plt.plot(result['2016-7':'2016-9'].index,result.loc['2016-7':'2016-9','simple regression'])
plt.plot(result['2016-7':'2016-9'].index,result.loc['2016-7':'2016-9','fama_french'])
plt.plot(result['2016-7':'2016-9'].index,result.loc['2016-7':'2016-9','sample'])
plt.legend()
plt.show()
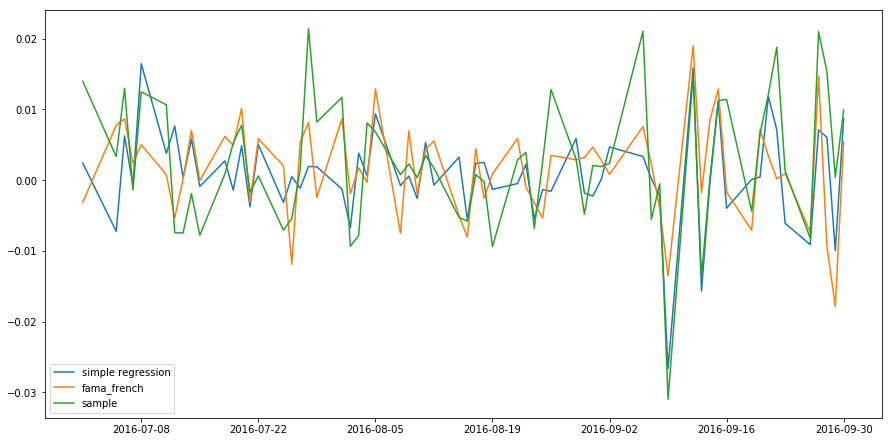
Although it's hard to see from the chart above, the predicted return from multiple regression is closer to the actual return. Usually we don't plot the predictions to determine which model is better; we read the summary table.
Model Significance Test
Instead of using to assess whether our regression model is a good fit to the data, we can perform a hypothesis test: the F test.
The null and alternative hypotheses of an F test are:
We won't explain F test procedure in detail here. You just need to understand the null and alternative hypotheses. In the summary table of an F test, the 'F-statistic' is the F score, while 'prob (F-statistic)' is the p-value. Performing this test on the Fama-French model, we get a p-value of 2.21e-24 so we are almost certain that at least one of the coefficient is not 0.
If the p-value is larger than 0.05, you should consider rebuilding your model with other independent variables.
In simple linear regression, an F test is equivalent to a t test on the slope, so their p-values will be the same.
Residual Analysis
Linear regression requires that the predictors and response have a linear relationship. This assumption holds if the residuals are zero on average, no matter what values the predictors take.
Often it's also assumed that the residuals are independent and normally distributed with the same variance (homoskedasticity), so that we can contruct prediction intervals, for example.
To check whether these assumptions hold, we need to analyse the residuals. In statistical arbitrage, residual analysis can also be used to generate signals.
Normality
The residuals of a linear model usually has a normal distribution. We can plot the residual's density to check for normality:
plt.figure()
#ols.fit().model is a method to access to the residual.
fama_model.resid.plot.density()
plt.show()
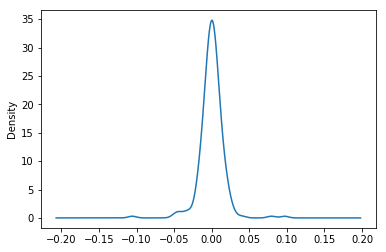
As seen from the plot, the residual is normally distributed. By the way, the residual mean is always zero, up to machine precision:
print(f'Residual mean: {np.mean(fama_model.resid)}')
[out]: Residual mean: -2.31112163493e-16
print(f'Residual variance: {np.var(fama_model.resid)}')
[out]: Residual variance: 0.000205113416293
Homoskedasticity
This word is difficult to pronounce but not difficult to understand. It means that the residuals have the same variance for all values of X. Otherwise we say that 'heteroskedasticity' is detected.
plt.figure(figsize = (20,10))
plt.scatter(df.spy,simple.resid)
plt.axhline(0.05)
plt.axhline(-0.05)
plt.xlabel('x value')
plt.ylabel('residual')
plt.show()
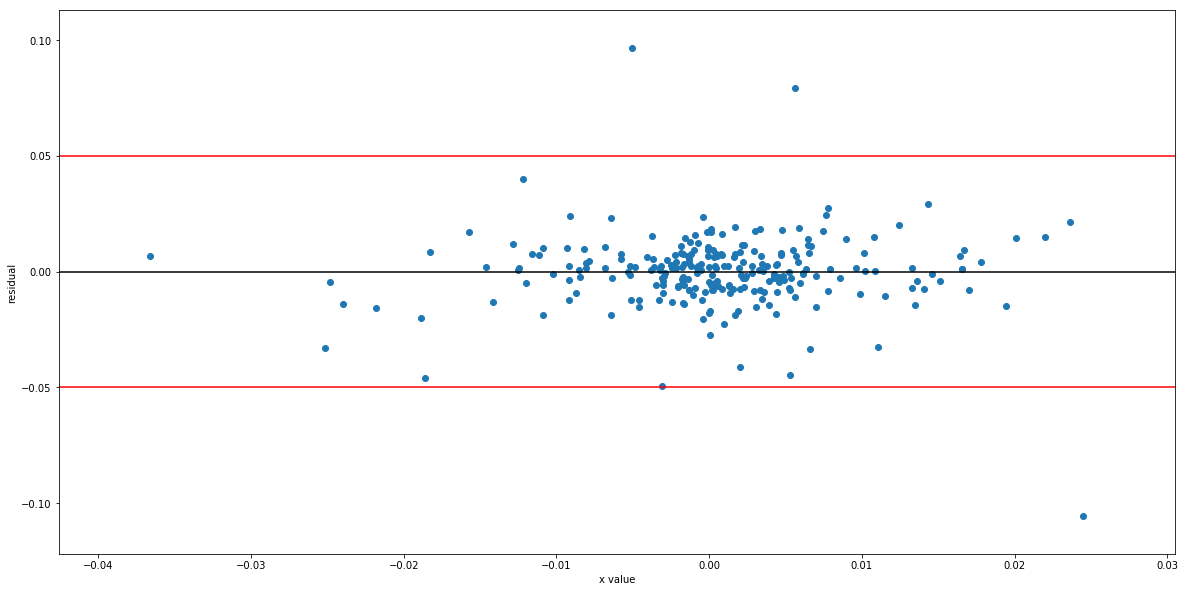
As seen from the chart, the residuals' variance doesn't increase with X. The three outliers do not change our conclusion. Although we can plot the residuals for simple regression, we can't do this for multiple regression, so we use statsmodels to test for heteroskedasticity:
from statsmodels.stats import diagnostic as dia
het = dia.het_breuschpagan(fama_model.resid,fama_df[['MKT','SMB','HML','RMW','CMA']][1:])
print(f'p-value: {het[-1]}')
[out]:p-value of Heteroskedasticity: 0.144075842844
No heteroskedasticity is detected at the 95% significance level.
Summary
In this chapter we have introduced multiple linear regression, F test and residual analysis, which are the fundamentals of linear models. In the next chapter we will introduce some linear algebra, which are used in modern portfolio theory and CAPM.
ON THIS PAGE
Share



QuantConnect™ 2022. All Rights Reserved